Lendo e Escrevendo Dados
A habilidade de ler e escrever dados é fundamental para trabalhar com qualquer ciência de dados. A maioria dos tipos básicos de dados são texto e CSV (Comma Separated Values).
O código de exemplo lê um arquivo de texto e limpa o processo. Em seguida lê um arquivo de texto pré-limpo, salve-o como um arquivo CSV, leia o arquivo CSV, converta para uma lista de elementos OrderedDict, e converta essa lista para a lista de elementos regulares do dicionário.
Faça o download da pasta data para o exemplo funcionar.

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
import csv def read_txt(f): with open(f, 'r') as f: d = f.readlines() return [x.strip() for x in d] def conv_csv(t, c): data = read_txt(t) with open(c, 'w', newline='') as csv_file: writer = csv.writer(csv_file) for line in data: ls = line.split() writer.writerow(ls) def read_csv(f): contents = '' with open(f, 'r') as f: reader = csv.reader(f) return list(reader) def read_dict(f, h): input_file = csv.DictReader(open(f), fieldnames=h) return input_file def od_to_d(od): return dict(od) if __name__ == "__main__": f = 'data/names.txt' data = read_txt(f) print ('text file data sample:') for i, row in enumerate(data): if i < 3: print (row) csv_f = 'data/names.csv' conv_csv(f, csv_f) r_csv = read_csv(csv_f) print ('\ntext to csv sample:') for i, row in enumerate(r_csv): if i < 3: print (row) headers = ['first', 'last'] r_dict = read_dict(csv_f, headers) dict_ls = [] print ('\ncsv to ordered dict sample:') for i, row in enumerate(r_dict): r = od_to_d(row) dict_ls.append(r) if i < 3: print (row) print ('\nlist of dictionary elements sample:') for i, row in enumerate(dict_ls): if i < 3: print (row) |
Caso você estiver utilizando a versão 2 do Python o seguinte erro irá aparecer:
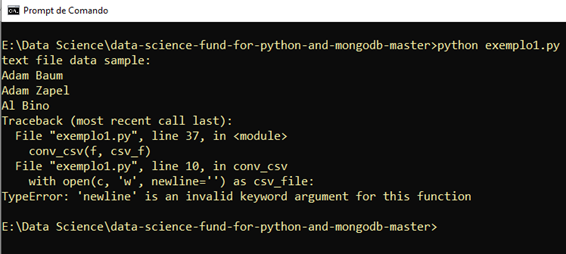
Se você executar com a versão 3 do Python, aí sim, funciona:
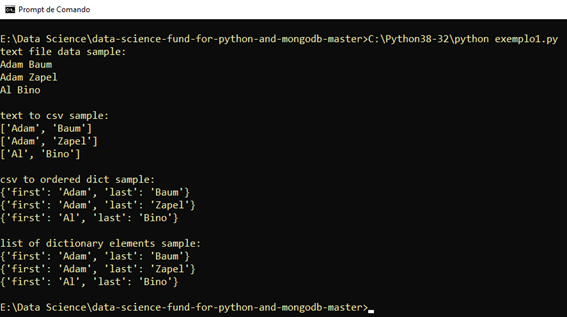
Fonte livro: Data Science Fundamentals for Python and MongoDB